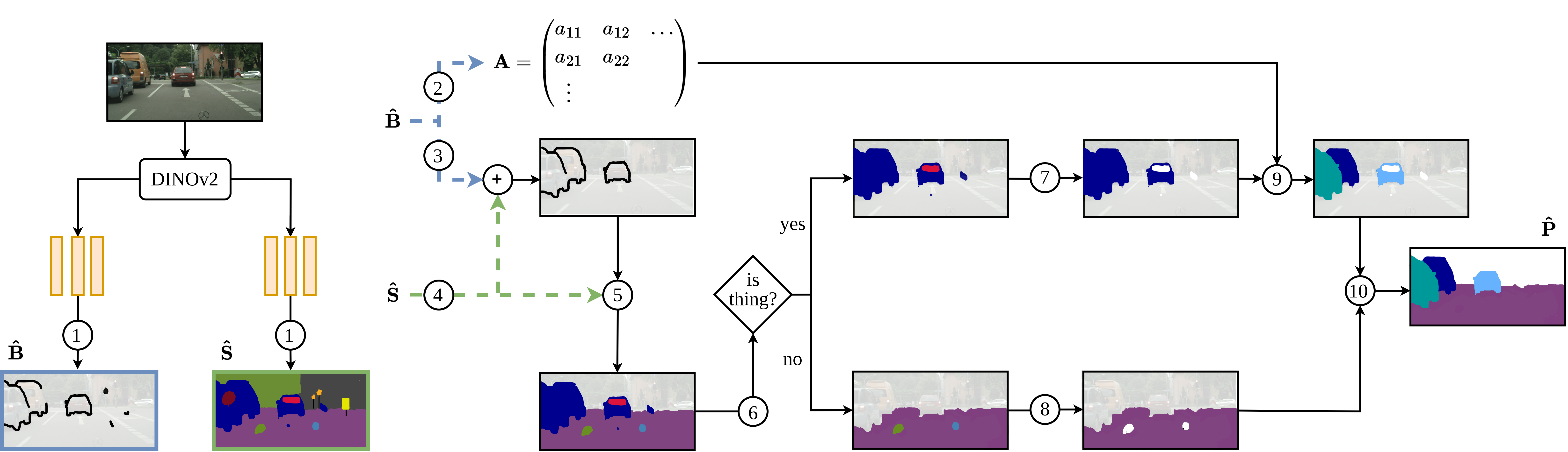

A key challenge for the widespread application of learning-based models for robotic perception is to significantly reduce the required amount of annotated training data while achieving accurate predictions. This is essential not only to decrease operating costs but also to speed up deployment time. In this work, we address this challenge for PAnoptic SegmenTation with fEw Labels (PASTEL) by exploiting the groundwork paved by visual foundation models. We leverage descriptive image features from such a model to train two lightweight network heads for semantic segmentation and object boundary detection, using very few annotated training samples. We then merge their predictions via a novel fusion module that yields panoptic maps based on normalized cut. To further enhance the performance, we utilize self-training on unlabeled images selected by a feature-driven similarity scheme. We underline the relevance of our approach by employing PASTEL to important robot perception use cases from autonomous driving and agricultural robotics. In extensive experiments, we demonstrate that PASTEL significantly outperforms previous methods for label-efficient segmentation even when using fewer annotation.